

Thinking About AI: Part IV - How It Works
We continue our series on AI, focusing on how it works and the implications of how it works.

Welcome Back to Win-Win Democracy
The frenzied discussion of AI — what it can do for us, what it will do to us, what we should do to control it, and who stands to benefit from it — continues in the media. There are no definitive answers to many of the most important questions, which require predicting the future.
The purpose of this issue is to give you some intuition about how the new generation of AI works, specifically GPT-3, which is the core engine behind ChatGPT. I believe that this intuition will give you a basis with which to evaluate what you read and hear in the media.
This stuff is complicated so I’m going to simplify — a lot.
I recognize, however, that some of you have technical backgrounds and may want to put in the time to understand the technology at a deeper level, so I will point you at the technical resources I’ve found most helpful for my own learning.
Helpful Technical Resources
Skip to the section called Large Language Models unless you want pointers to more detailed technical information or want to understand the sources I’ve used.
There are plenty of detailed technical papers in the literature if you want full details, at least what is known publicly. Without up-to-date and deep knowledge of the field, however, they are tough reading. Both Stephen Wolfram and Jay Alammar have produced excellent material to help those who are generally comfortable with technical material but not working in AI.
Stephen Wolfram
Wolfram — yes, the Wolfram of Wolfram Alpha — wrote a longish (105 pages when “printed” to PDF), but readable, paper in February 2023 that gives an overview of models, neural networks, and how ChatGPT and GPT-3 work. This same material is also available in Wolfram’s 2023 book What Is ChatGPT Doing ... and Why Does It Work?. The book includes additional material about how Wolfram’s company is planning to integrate Wolfram Alpha with ChatGPT and why he believes that’s important.
Jay Alammar
Alammar is a prolific blogger on topics related to machine learning and AI. He also has a YouTube channel with excellent videos on the same topics.
His blog post How GPT3 Works - Visualizations and Animations is an excellent starting point and includes links to his other relevant works, which I’ve also found helpful. His summary video is a good starting point:
I will use some of Alammar’s figures in my explanation. He generously makes his work available for non-commercial use through the Creative Commons Share-Alike license. Likewise, this newsletter issue is available under the same license.
Large Language Models
ChatGPT, and GPT-3 on which it is based, is an example of a large language model (LLM). It is a model in the sense that we discussed last last time: Given an input it computes an output that estimates something about the input. The important word is “computes.” Seeing what ChatGPT does, we might naturally tend to use anthropomorphic words like “thinks” but it is important to remember that, literally, these systems are doing a massive amount of computation to produce estimates, which makes them appear “intelligent”, whatever that means.
Our model last time was simple and small: Given two facts about a particular house, it used a simple equation with three weights to produce an estimate of that house’s value. As we discussed, that model was too simplistic to be able to give accurate estimates. A realistic model would require more information about each house and would be a more complex equation with more weights.
Similarly, GPT-3 takes text as input and estimates which words are most likely to appear next. If you’ve typed on a phone or use Gmail, you’ve probably seen something like this: As you type the phone suggests a few words that might appropriately follow what you’ve already typed.
The difference between what your phone does and what GPT-3 does is that GPT-3 looks at long sequences of text, up to several thousand words at a time. This allows its estimates of the likelihood of the following word to be based on a lot of context, not just the last few words.
Alammar uses a cute example throughout his animations and diagrams; I’ll use that same example.
The great science-fiction writer Isaac Asimov coined the “three laws of robotics” in 1942.
Prompt ChatGPT to recite the first law and you get:
Prompt: recite the first law of robotics
Response: The first law of robotics is: "A robot may not injure a human being or, through inaction, allow a human being to come to harm." This law is one of the three fundamental laws of robotics, which were first introduced in the science fiction stories of Isaac Asimov. The first law establishes that a robot's primary responsibility is to ensure the safety of human beings, and that it must not take actions that could harm them.
Unlike traditional internet searches, ChatGPT doesn’t simply find web pages that might be relevant to show you. Instead, based on its LLM, it estimates what words should follow the prompt.
How does it do this?
The model has 175 billion weights — hence the adjective “large” — that it uses to compute the estimate.
Training the Model
Initially, the weights are random and the model is ignorant. Training, which consists of feeding the model huge amounts of text, gives the model its initial knowledge, which is captured in the setting of the weights.
The first phase of training feeds GPT-3 huge amounts of text — 300 billion1 “tokens”. A “token” is a word or, in some cases, portion of a word. For our purposes, just think of the training input as 300 billion words. These words were taken from sources on the Internet that have in one way or another been curated or filtered by humans2. This training is unsupervised, meaning that the system is not told by its human trainers what the correct answer(s) are.
Instead, as more data is fed into the model, the training algorithm adjusts the weights so that the estimates of the likelihood of a particular word following the text already seen get better and better. Again, this is all just math — nothing magic — that gives the procedure for adjusting the weights.
But this takes a staggering amount of computing power. Training GPT-3 on the 300 billion tokens requires about 3.14 x 10²³ floating point operations3, estimated to require 355 GPU-years4 and costing $4.6 million per training run.
Once this initial training is completed, the results are further improved by supervised training, in which many examples, each labeled with the correct output, are given.
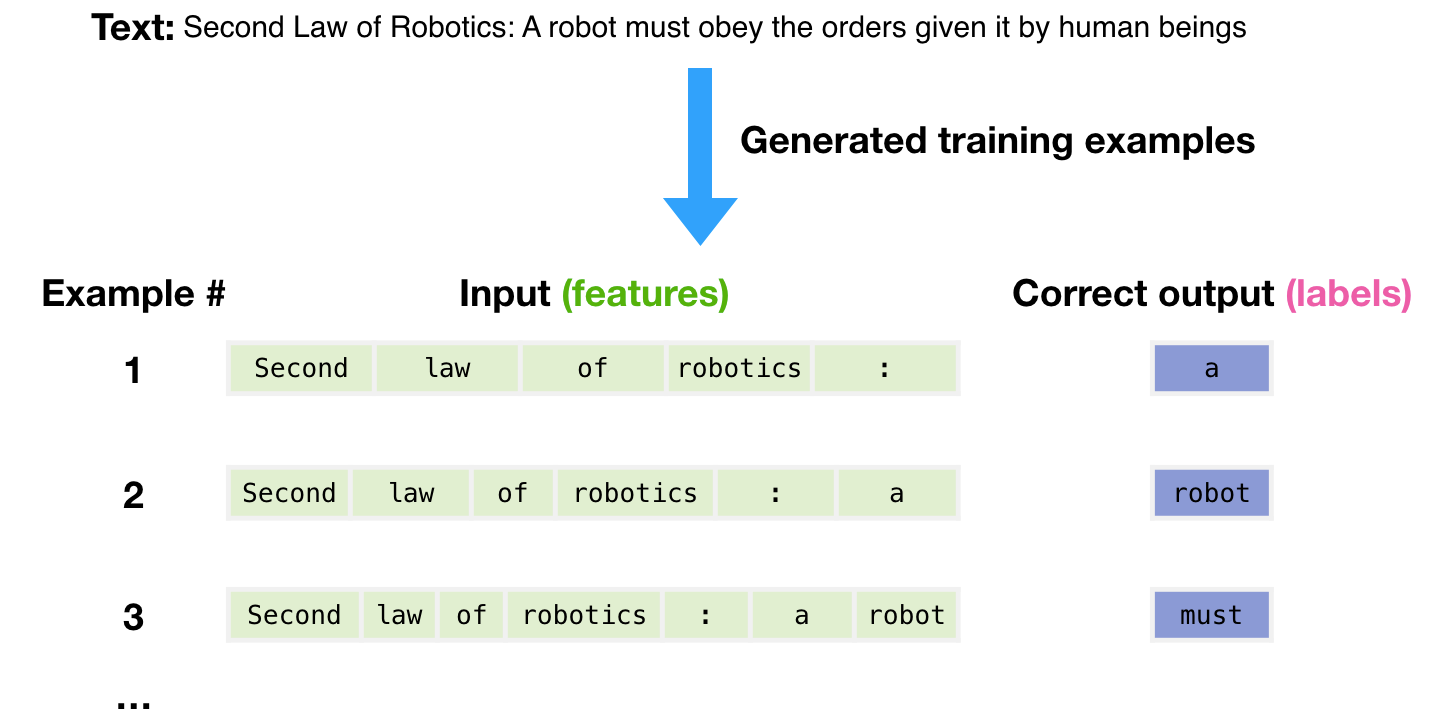
If the model produces the wrong output, that information is used to update the weights to improve the results. This is done millions of times to improve the model’s ability to estimate what word is likely to come next.
How Does the Model Work?
What’s going on in the model itself? The real answer to this question is complex, full of important details, and beyond the scope of what we need to understand. But I want to give you a simplified sense of what the model is like.
Artificial Neural Network
The model is an artificial neural network (ANN). ANN’s work with numbers. Recall from last time that each artificial neuron in an ANN receives inputs from other neurons, multiplies those inputs by weights, and adds those numbers together, to get its output, which is sent along to other artificial neurons. When the model is trained, it is those weights that are being determined. This is just arithmetic.
The neurons are connected together in a network in which the outputs of some neurons feeds into the inputs of other neurons. The network is organized into layers, something like this:
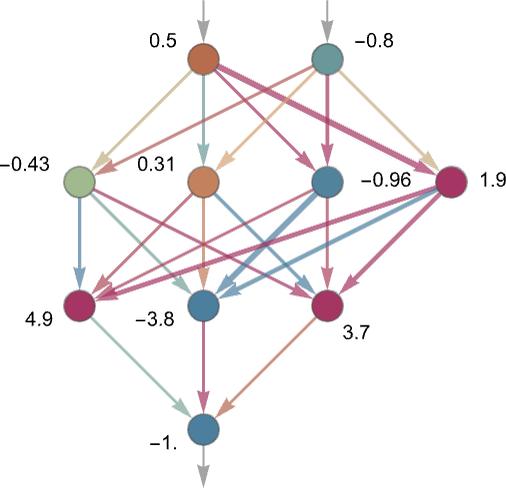
You feed in numbers at the top and numbers are produced at the neurons in each layer, and ultimately a number comes out of the bottom.
Embeddings
Numbers. But we’re working with words. There are about 50,000 commonly used words in English, so we could just look in the dictionary and give the words successive numbers. That gives us numbers, but the numbers don’t mean anything: Word n and word n+1 having similar numbers doesn’t mean that the words mean something similar.
Instead, the model works with an embedding, which represents each word as a vector of numbers (if you don’t know what a vector is, just think of it as a list of numbers). The important part of an embedding is that words with similar meanings have vectors that are near each other.
Let’s illustrate this with vectors of length 2. Think of the two numbers for each word as coordinates on a graph. You could get something like this:

Now, when the embeddings of words are near each other, those words are somehow related to each other.
Of course, we need way more than 2 numbers for each word. In fact, ChatGPT uses vectors consisting of 12,288 numbers for each word5. Where do those numbers come from? Yes, you guessed it. The embedding is computed by the neural network, which "learns" how to do this as its weights are learned through training.
Transformer Structure
A transformer is a particular structure of neural network that allows the neural network to pay “attention” to the context needed to make certain decisions. Consider this sentence: “The animal didn’t cross the street because it was too tired.” You’d think that the encoding for “it” in this sentence depends on whether “it” refers to “animal” or “street”. The transformer mechanism provides a way to “pay attention” to the proper context so that a suitable embedding is computed.
The GPT-3 model starts with an encoder, a neural network structure that computes the embedding of the input, which consists of 2048 tokens (think, roughly, words). Then there are 96 layers of the neural net mechanism that pays “attention”, stacked so that the output of one layer feeds into the next layer. Out of the bottom comes the embedding of the predicted next word, i.e., the 12,288 numbers for that word. Finally, there is a decoder, a neural network structure that converts the word’s embedding back into the word.
All of this (and much more) can be expressed in terms of matrix computations, which modern computers, especially the graphical processing units used in AI, do extremely fast.
Summary of the Model
Ultimately, the model is a very large neural network with 175 billion weights, which are learned during the training process. The particular structure of the model has been determined by a combination of theory and trial-and-error engineering to capture the essence of language in a form that can be trained with a reasonable amount of effort.
How is the Model Used?
The prompt text is fed into the model, which then predicts the most likely next word. That word is fed back into the input and the next word is predicted from the new text.
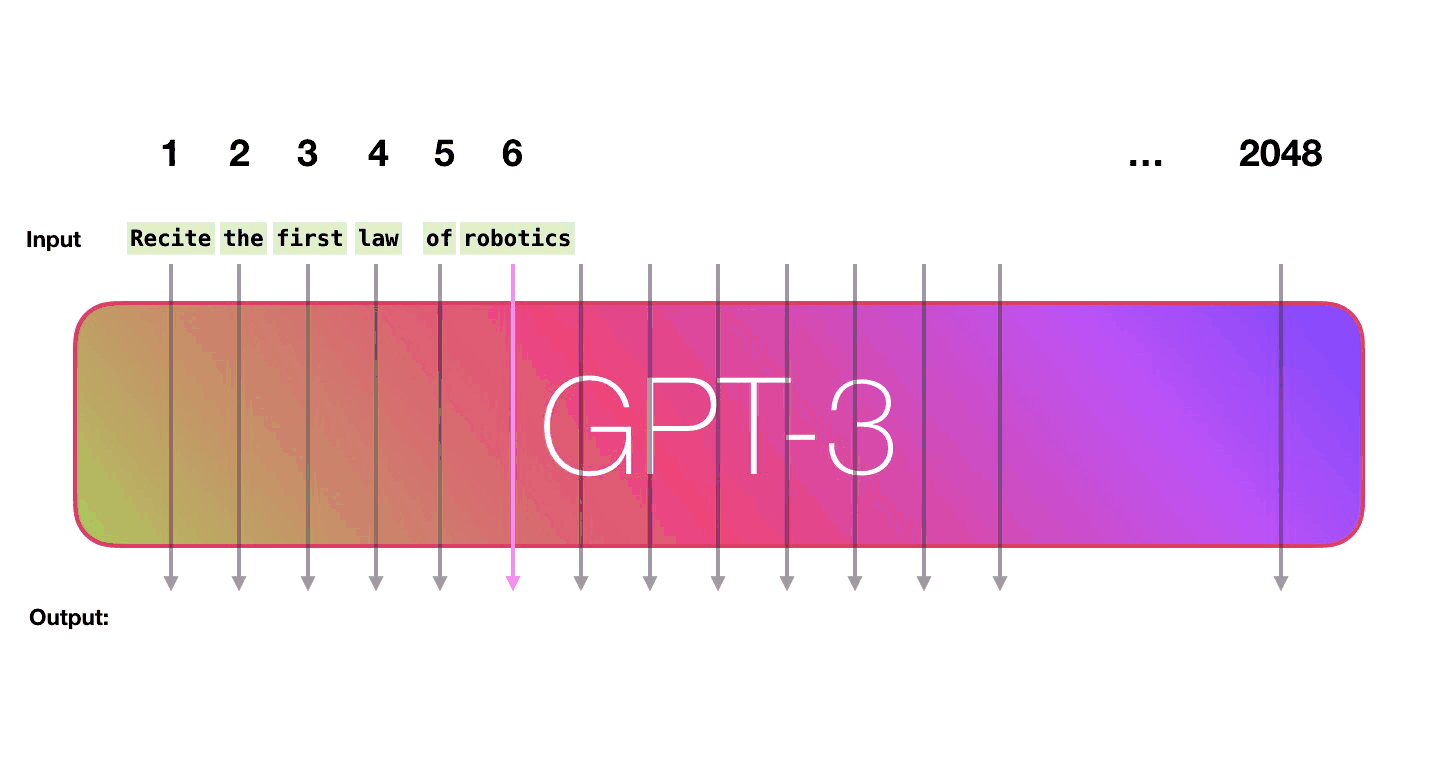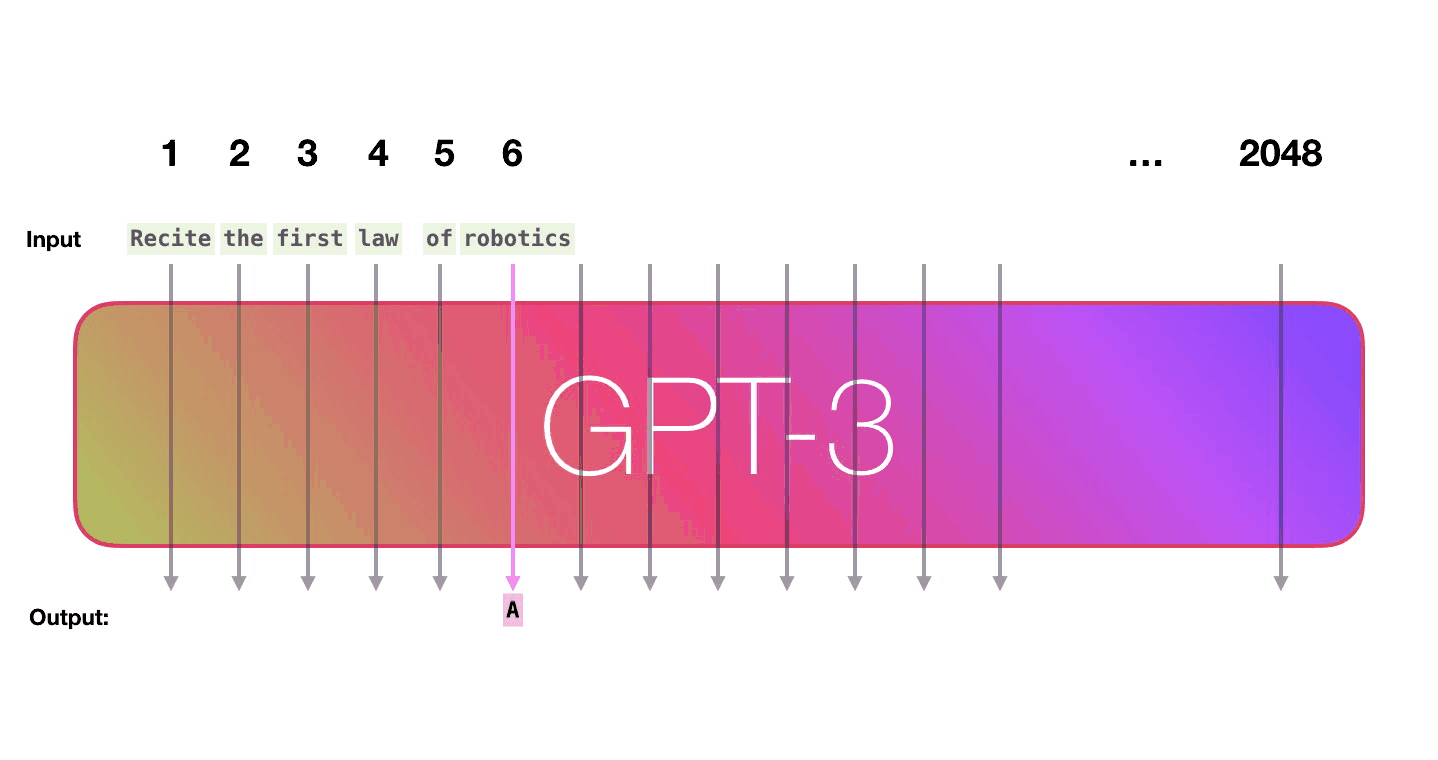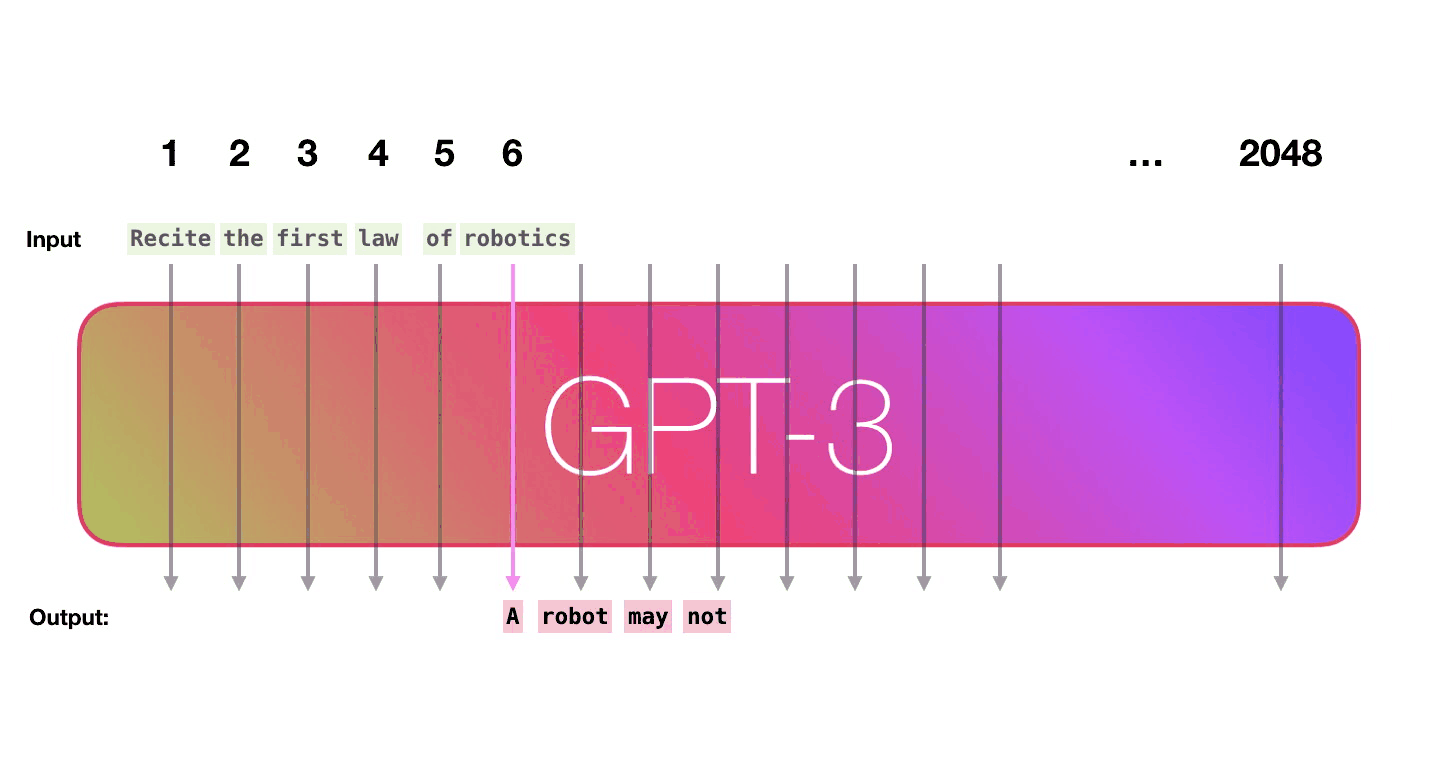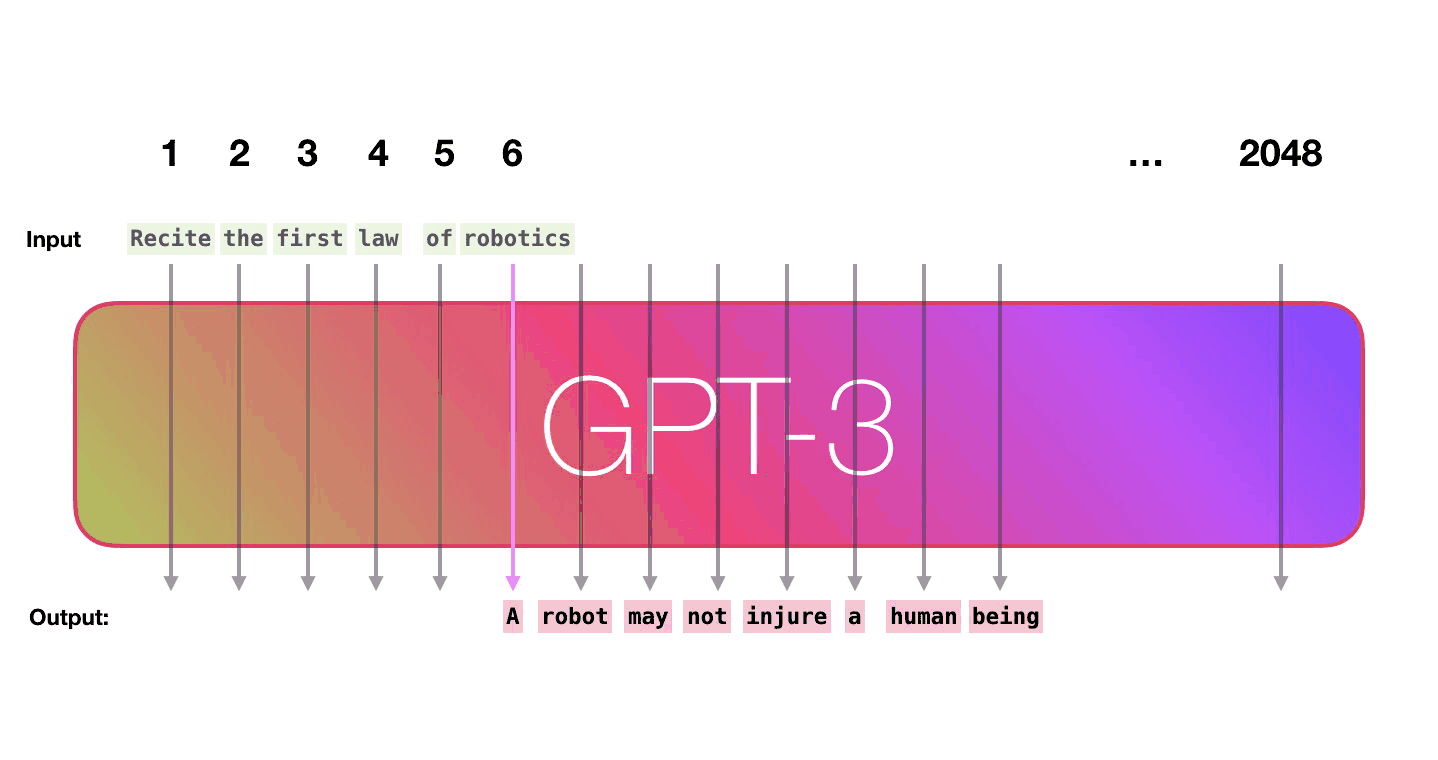
That’s it.
What’s remarkable is that this process built around a massive number of simple artificial “neurons” can produce human-like language capabilities.
Fine-Tuning and Alignment
The trained GPT3 model “knows” a lot about language but is not tailored in any way toward specific tasks. For example, it could be used as the basis for a chatbot (like ChatGPT), a news summarizer, or a language translator, among many other possibilities.
For specific purposes, the model can be subjected to additional training to adjust the model’s weights to improve its suitability in particular applications.
Additional training with human feedback can also be used to align the model with users’ intentions and expectations. A human, for example, might not want to be exposed to racist diatribes that a chatbot might produce based solely on the text with which it has been trained.
Additional training, called reinforcement learning from human feedback (RLHF), can be used to fine-tune GPT3 to encourage responses that align with human preferences and to inhibit responses that offend human preferences. Experiments have demonstrated that RLHF fine-tuning can improve truthfulness and reduce toxic output while having little effect on other desired aspects of the output.
Conclusions
Now that we have an inkling of how GPT-3 and ChatGPT work, what can we conclude?
Language Capabilities
ChatGPTs language capabilities derive from essentially a statistical analysis of huge samples of human writing. It writes convincingly and confidently.
It can “speak” in a variety of voices in a way that I find remarkable. Consider this exchange:
Prompt: In the voice of Donald Trump, write a tweet about tax increases.
Response: "The Democrats want to RAISE your taxes! This is a disaster for hardworking Americans who deserve to keep more of their own money. We need to CUT taxes, not increase them. Let's make America great again and put more money back into the pockets of the people! #MAGA #taxcuts"
Prompt: In the voice of Joe Biden, write a tweet about tax increases.
Response: "Here's the truth: we need to invest in our country's infrastructure, education, and healthcare. And that means asking the wealthiest Americans and corporations to pay their fair share in taxes. It's time we prioritize the middle class and build back better for all Americans. #taxfairness #BuildBackBetter"
Now that’s bipartisan capability!
No Logical Thinking
Appearances can be deceiving. It “writes” solely based on the statistics of the vast amounts of text it has “read.” It is not endowed with any logical thinking ability.
Consider this exchange with ChatGPT (the prompts are from Colin Fraser’s ChatGPT: Automatic expensive BS at scale):
Prompt: A spozit is a type of poem that has three lines. The first line is two words, the second line is three words, and the final line is four words. Write a spozit about animals.
Response:
Wild eyes stare fiercely,
Razor teeth gleam brightly,
Nature's perfect killers.Prompt: Is that a valid spozit?
Response: I apologize, that was not a valid spozit. Here's a valid spozit about animals:
Furry paws patter,
Whiskers twitch in the night,
Nature's stealthy hunters.
(Interestingly, the ChatGPT’s responses are different than the ones that Fraser reported for the same prompts6.)
Fraser made up spozits, so the model had never seen that word before. That doesn't matter to you or I. We understand the instructions and know what is wanted. But, it turns out that even without introducing spozits, ChatGPT can’t follow simple, logical instructions, as illustrated this prompt of mine:
Prompt: Write a three-line poem about animals with the first line two words, the second line three words, and the final line four words.
Response:
Crouched low,
poised, Golden eyes gleaming,
Tawny hunter's stare.
Poetry, yes! Following simple, logical instructions, no!
Why? ChatGPT doesn’t have any sort of logical “engine”. This also fits with what we saw when I asked it to solve a simple algebra word problem.
Confident Lying / Hallucination / Fabrication
ChatGPT lies with aplomb. Perhaps “lie” is too strong a word — the definition of “lie” is making an intentionally false statement. ChatGPT has no intention. It just responds based on the statistics of its training text. On the other hand, since most of us humans tend to anthropomorphize when talking about AI, turnabout is fair play.
Seriously, in our first article on AI, we saw several examples where ChatGPT responded to straightforward prompts with well-written nonsense. Consistent with our tendency to anthropomorphize, the AI literature calls this hallucination.
The reality, however, is that ChatGPT doesn’t have any knowledge base beyond the statistics of the use of language with which it was trained.
This can have serious consequences. Both Fox News and the Washington Post reported last week that, in response to a prompt to generate “a list of legal scholars who had sexually harassed someone,” ChatGPT wrote that a law professor had sexually harassed a student while on a class trip to Alaska, citing a Washington Post article. The problem: The cited article didn’t exist and there had been no trip to Alaska.
ChatGPT can fabricate events that never happened, potentially causing serious consequences to innocent people.
No Explainability
If you read something I write and you think that I’m incorrect, you can ask me to explain my thinking. I might not be able to convince you that I’m correct, but at least I’ll be able to tell you how I arrived at my position. When ChatGPT writes something there’s no way for a human being to understand how ChatGPT arrived at its conclusions.
What’s Next?
In the next issue, I will begin discussing the impact of AI technology, starting with speculating on where this technology is headed and how it might be deployed.
Table 2.1 in Language Models are Few-Shot Learners.
The details are interesting but beyond our scope. See Section 2.1 of Language Models are Unsupervised Multitask Learners.
Table D.1 in Language Models are Few-Shot Learners.
GPUs are graphical processing units, originally designed to do the computations required to produce realistic-looking computer graphics, but now repurposed for AI computations. The computation for training would require 355 of the most powerful GPUs operating for a year. Alternatively, more GPUs could do the computations in less time.
ChatGPT introduces an element of randomness based on a concept called temperature. Instead of always choosing the word considered most likely, it will choose a word that is somewhat less likely. This supposedly makes its output more interesting.
Thanks Lee. Appreciate the pointer to Jay Alammar - great visualizations. I liked and subscribed to his YouTube channel. His video on word embeddings is also quite well visualized. The word guessing game of "Twenty Questions" is also a way of thinking about words as a vector of numbers corresponding to "yes" or "no" or finer shades to specific questions. An early AI that was quite impressive (built into toys) used this type of approach is described here: https://en.wikipedia.org/wiki/20Q