

Thinking About AI: Part III - Machine Learning and Artificial Neural Networks
We continue our series on AI, focusing on how machine learning and artificial neural networks let machines perform tasks that are effortless for humans but used to be impossible for machines.


Welcome Back to Win-Win Democracy
When I was a Ph.D. student in Computer Science in the late 70’s and early 80’s, many extremely smart students, faculty, and scientists at top universities and research labs were hard at work tackling AI problems like recognizing objects in images, transcribing speech from audio into text, generating speech from text, getting robot arms to manipulate objects, and developing ways to store and retrieve “knowledge” (whatever that means). It was an exciting time.
In retrospect, despite incredible advances on many fronts, these problems were much harder to solve than expected: Good, practical, affordable solutions didn’t become available until the 2010 decade.
Understanding how these problems were originally tackled, and why new approaches are more effective, will help you understand some of the strengths and weaknesses of today’s AI.
Although there’s a lot of interesting mathematics and engineering behind these efforts, I’m going to keep the discussion as intuitive as I can while still getting across some key ideas.
Stuff People Do Effortlessly
You see a picture and you immediately, without any conscious effort or thought, recognize people, animals, landscapes, etc. Beyond recognizing categories of objects, you effortlessly recognize specific people, animals, and places that you know or even have just seen once before. You do this under various lighting conditions, partial obscuration, and from various angles, rotations and geometric distortions.
Likewise, when you hear speech in your native tongue, even in a noisy environment, you understand the words being spoken, perhaps recognize who’s speaking, perhaps understand the speaker’s emotions, and glean meaning from the sequence of words. You have no difficulty interpreting ambiguous words in speech like this:
Conversely, when you want to say something to another person, you control your breath and move your tongue, jaw, lips, and larynx in complex ways that produce the sound that comprises your speech. You can modulate the quality of that sound to express emotion. You can string together words that conform enough to your language’s grammatical structure that others can understand your meaning, but you do this without conscious thought about grammar; indeed, many of us don’t even know explicitly the rules (and exceptions) of our language’s grammar.
You reach for a glass on your desk that you remember is behind your laptop screen but which you can’t see.

Without thinking about it, you contract the muscles that pivot your arm in your shoulder, bend your elbow, move your fingers to grasp the glass, exert sufficient force to hold the glass but not so much to break it, and bring it from behind the laptop screen, around the screen’s side and toward your mouth.
You also have tremendous knowledge about how the physical world works. We can judge the relative velocity of an object in relation to our body and know how to respond.
Most of us know that we can walk on wood but not on water.
Beyond recognizing the sight, sound, and probably smell of a few important people in their lives, newborns can’t do any of this. But, it doesn’t take long for a child to learn these skills. My three-year-old granddaughter can do all of these things.
There are other skills that older children and adults acquire through sustained, intentional effort, but once the skill is learned, using it is similarly effortless. Reading is such a skill. When children learn to read they first learn to recognize letters, to associate sounds with individual letters and letter sequences, to put those sounds together into words, and, ultimately, to be able to recognize words and even phrases on sight with no conscious effort.
When you stop and think about it, the effortless skills we humans have and can learn are remarkable.
Classical Approaches to Automating the Effortless Stuff
As computers developed in the 1960s and beyond, artificial intelligence researchers worked hard to endow computers with some of these same capabilities. Without going into much detail, it is instructive to discuss the general approaches taken and why, despite a lot of sophisticated efforts, they didn’t work very well.
When I say “classical approaches”, I mean the 20th century work. As I’ll describe below, big advances happened this century that changed the whole ballgame.
Computer Vision
Let’s start with what is often called computer vision. Roughly speaking, this encompasses acquiring images, processing them in various ways, and extracting information from the processed images — what objects are in the image, measuring properties of the objects, etc. It was initially thought that this would be easy — the Wikipedia article on computer vision refers to the 1966 Summer Vision Project at MIT, which aimed at the “construction of a significant part of a visual system.”
By the time I studied computer vision as a graduate student in the late 1970’s, the field had advanced a lot but was nowhere close to achieving a “significant part of a visual system.” Hubel and Wiesel had shown earlier in experiments with cats that the visual cortex contains detectors for edges and lines in various orientations. Following nature’s lead, computer vision researchers developed algorithms to detect many types of features, including edges, in images.

Finding edges is great, but how do you use the edges to “understand” the picture?
A person effortlessly recognizes a young girl holding a flower. But how do you get a computer to do that? Maybe you write some rules about looking for things that look like eyes, nose, and a mouth. But, how do you get those rules to still recognize the girl if she turns her face to the right so that you only see one of her eyes? Or if her hair completely covers an eye. And what are the rules for a flower that would still work if she were holding a yellow rose instead?
Many approaches have been developed. For example, maybe you can develop a deformable model of what a face looks like and somehow try to find the best fit between the model and the image. If the fit is good enough, then you’ve found a face. But with the huge variation in what faces (flowers, whatever) look like, how they’re positioned, lit, and partially obscured, this is extremely challenging.
Speech Transcription
Problem: create a machine that can listen to sound containing human speech and transcribe it into text. As with computer vision, this was originally thought to be an easy problem. But, there are many challenges.
When you and I speak, even saying the same words, the actual audio signals we produce are quite different, even if we’re speaking in otherwise silent environments. What allows someone to interpret those different audio signals to be the same words?
Classical speech transcription worked with the idea of formants, which correspond to various peaks in the frequency spectrum of the acoustic signal. Certain patterns of formants yield particular phonemes of speech. Formants are also connected to resonances in the vocal tract, which change as one speaks.
In some ways, formants in acoustic signals are like edges in images. The idea is that if you can find the formants (not too hard in quiet environments) then you can somehow put them together into phonemes and then words. It is the putting together that turns out to be hard, although some statistical techniques showed promise.
The problem becomes even harder with background noise, poor quality audio, or several people speaking at once (e.g., a party).
Robot Motion Planning
Suppose you want to command a robot arm to pick up a glass like I did in the video snippet above. First, the robot needs to locate the glass, perhaps using computer vision. Then, somehow, the robot system has to plan which joints it is going to move, how much, with what force, and in what sequence. It has to be aware of obstacles to work around. It might even be working in an environment where the obstacles are moving or unknown. What should it do if part of the robot bumps into something unexpected? What if the glass starts to fall as it is being grasped?
Classical robotics research devised algorithms to figure out the appropriate movements in ideal situations, where the positions of all obstacles are known and fixed and the position and shape of the object you want it to grasp is also known. There are even algorithms that will plan the motion of multiple robots working simultaneously in one workspace.
All of these algorithms require a good “model” of the environment in which the robot is moving and considerable computation time.
Classical robotics research also devised “languages” and “rules” with which to instruct robots what tasks to accomplish and how to respond when something doesn’t go as expected.
Now, imagine a self-driving car (just another kind of robot), which has to plan and execute its motion while moving at high speed through an exceedingly complex set of both fixed and moving “obstacles.”
How would one devise a set of rules to guide any of these robots?
Reading Handwritten Text
Here are images of some handwritten text from the IAM Handwriting Database1:



Humans who have learned to read handwriting can effortlessly read the three samples, even though there are huge differences in the the images.
Classical techniques for handwriting recognition work much like we discussed for classical computer vision: Define “features” to use to extract individual characters, then recognize which letter each character represents. The problem is that defining the features in a way that works across the huge variations in individuals’ handwriting is difficult.
The Common Thread Among Classical Techniques
I could go on with other examples, but I think that we’ve seen enough to be able to understand the common thread among the classical techniques:
Regardless of the “effortless task” we’re trying to automate, it is exceedingly difficult to define rules or algorithms that can attend to the essential aspects of the task and ignore the irrelevant differences.
Whether it’s handling variations in orientation, lighting, and partially-obscured objects in images, differences among the way that people write, differences in the sounds people produce when speaking, or planning the motion of a robot (including automated cars) in complex, changing, and unpredictable situations, people struggle to write rules or algorithms that capture the essence of the task.
Machine Learning
Learning: Babies do it; children do it; we do it. Why not machines?
Since it is so difficult for us humans to write rules or algorithms to implement the effortless tasks we humans do so easily, why not have machines learn, something like we all do?
The dramatic breakthroughs this century in the capabilities of machines to do the effortless tasks we’ve been discussing come from two important advances:
We don’t have to give machines rules or algorithms for how to do these tasks. Instead, we can train the machines to figure it out for themselves based on feeding them many examples (often found on the Internet).
Hardware originally developed to do the computation necessary to produce the amazing computer graphics — graphical processing units (GPUs) — to which we’ve become accustomed in video games, movies, and even our phones, can be repurposed to provide hitherto unimaginable amounts of computing power at incredibly low prices.
Basics of Machine Learning
The idea of a machine being able to “learn” sounds a bit like magic. But, really, it is just math. To give you some intuition about this, let’s look at an incredibly simple example.
Suppose you want to build a system to predict the value of a house based on certain information. To keep it (unrealistically) simple, let’s say that you could get a pretty good idea of a house’s value if you know m, the median house value in the census tract in which the home is located and s, the size of the house in square feet.
You might then compute the value v of a particular house with a simple equation
where a, b, and c are three constant numbers that express how much of a house’s value comes from where it’s located and how much from its size. For example, if you choose a to be .4, b to be 200, and c to be 1,000, then you’d estimate the value of a 1,500 square foot house located in a census tract with $200,000 median value to be $381,000.
An equation like this is called a model; a, b, and c are called the model parameters; and m and s are called the model features.
I just made up a, b, and c. How would you actually choose them? Well, maybe you could “teach” the system by feeding it lots of examples of real house value data, then the system could somehow figure out which single values of a, b, and c work “best” for computing home values from the model features of other houses.
This is an elementary example of machine learning: We feed the machine a bunch of examples — training data — and it learns how to estimate home values by choosing the model parameters a, b, and c. Once it knows the model parameters, it estimates the value of another house by simply plugging that house’s model features (median value and square footage) into the equation.
This is not far-fetched: It is an example of what’s called multiple linear regression, a common mathematical technique that’s widely used in statistics and other fields. Its originated in the early 19th century, has been studied extensively, and is easily implemented on computers.
Important Questions
But, I haven’t answered some important questions:
Where did that equation for the model come from?
How did I decide that median census tract house value and square footage would make good model features?
What does “best” mean? For example, do we prefer that most of the computed house values are pretty accurate but there may be a few that are way off, or do we prefer that there are no way-off estimates but the overall estimates might be a bit less accurate?
How much training data do we need to give the system for it to learn? Will more training data produce better estimates? How does the system learn about changes in the marketplace that could alter the estimates it should give?
How do the training data need to be distributed? Intuitively, if we trained with data from only a few neighborhoods, the estimates for houses in other neighborhoods might be way off.
Among these questions, the first two are most crucial.
I chose the simplest possible function of two variables2 to be the model. Even if the system learns the “best” possible values for a, b, and c, there’s no reason to think that the resulting estimates will be accurate. For example, suppose the value of extra square footage increases faster in expensive neighborhoods than in less expensive neighborhoods (I have no idea whether or not this is true). This model can’t capture that kind of effect.
Choosing the model features is also important. I would imagine that a house’s age might be important in estimating its value. Perhaps age should be a model feature too. I’m sure you can think of other potential model features that might be important in producing good estimates.
Engineering
Engineering a useful machine learning system requires choosing the model, the model parameters, and the model features. It requires finding or creating the training data, choosing suitable algorithms and hardware for running the training, and for producing the results.
Although this sounds daunting, the field has blossomed in the last twenty years and a wide array of ready-to-use machine learning capabilities are available for affordable prices on the web, as is expertise for hire.
Artificial Neural Networks (ANNs)
In 1943, Warren McCulloch and Walter Pitts, trying to understand how the relatively simple neurons in human brains work together to give us remarkably complex and effective behaviors, created a computational model of neurons. It looks something like this:
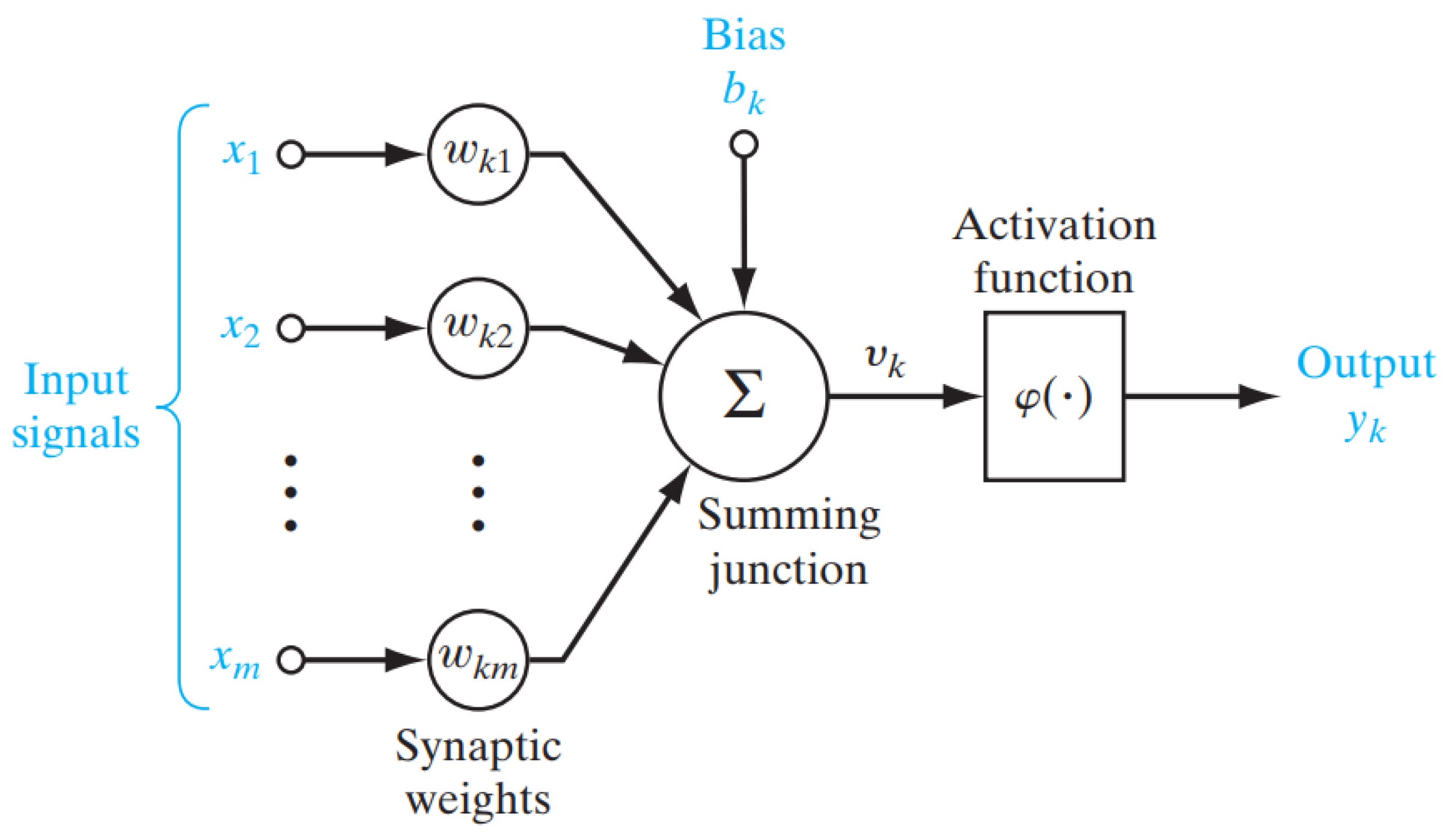
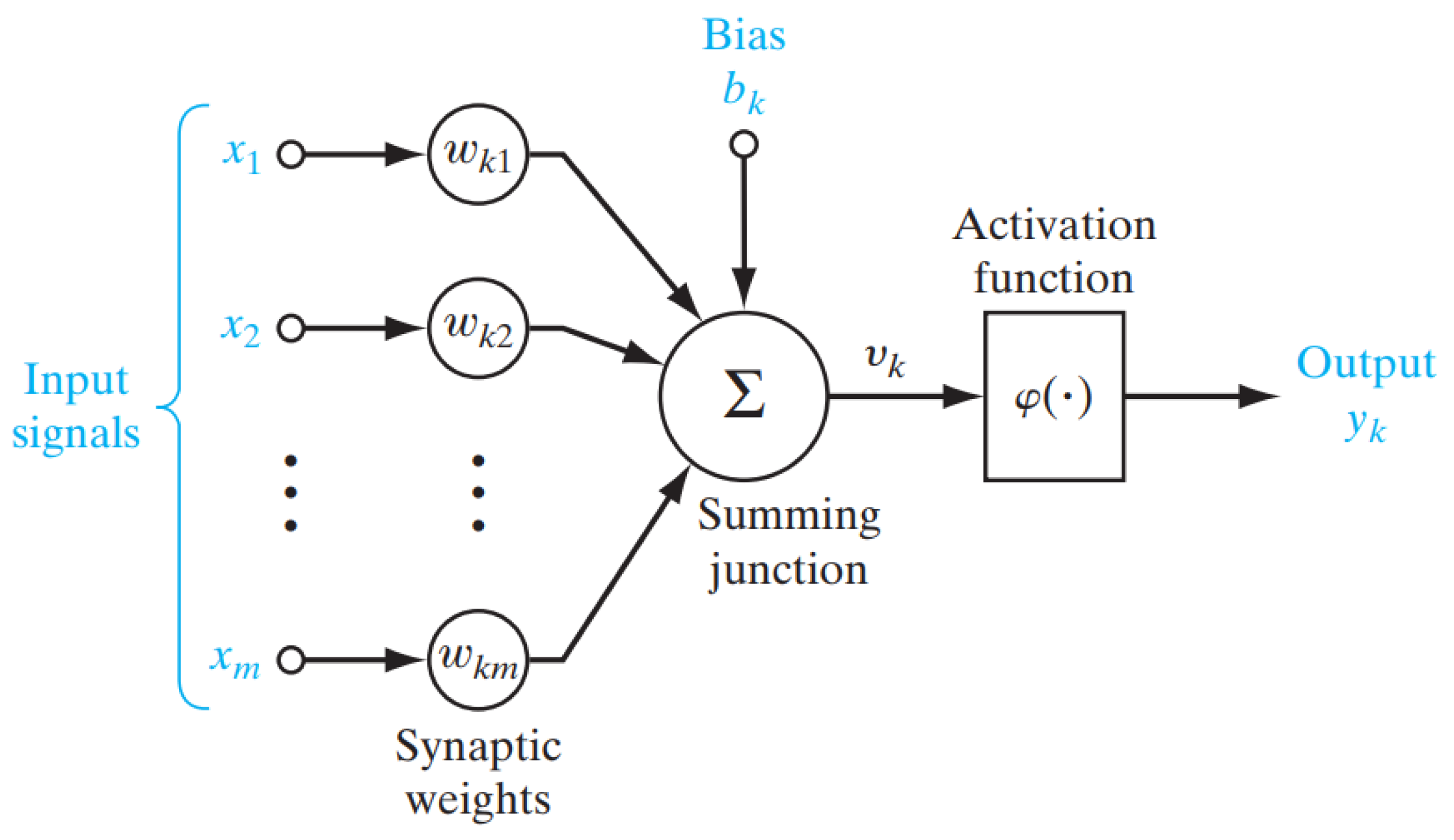{kind=link}
The input signals come from other neurons that are connected to this one. The inputs are multiplied by the weights and the results are summed. These are then passed through an activation function, which performs some additional computation to produce the output. The output is fed to other neurons.
In the 1960s, several researchers implemented artificial “neurons” motivated by this computation model and studied what networks of these artificial neurons could compute. After some disappointing results about what could be computed, work on artificial neural networks paused. It was restarted when it was realized that certain networks of these artificial neurons are capable of broad classes of computation.
Now here’s the exciting part: large networks of artificial neurons with appropriate activation functions (non-linear functions) can serve as models for a broad variety of situations, with the weights being found through a machine learning process. There are now well-developed algorithms for machine learning in ANNs that can be applied broadly.
Equally important, in the last ten years it has become possible to build extremely large artificial neural networks along with the processing power to train them on massive amounts of data. For example, the neural network employed in ChatGPT has 175 billion weights (yes, you read that correctly), which, of course, have all been learned by training.
Special kinds of artificial neural networks have been created for use in specific kinds of problems. Something called a convolutional neural network (CNN) is now widely employed in computer vision problems. CNNs can be trained with labeled images (e.g., this image contains a cat) to extract objects from images; they can also be used to automatically find facial “features” that can be used in face recognition. The use of CNNs has enabled dramatic improvements in computer vision. It is now routine to search for images containing certain objects in large libraries of photos.
Another recently-developed form of neural network called a deep feedforward neural network (DNN) has made it possible for machines to transcribe speech more accurately than humans.
The list goes on and on. Tremendous progress on all of the “effortless stuff” problems we’ve discussed has been made employing various forms of artificial neural networks and the now-available massive computing power.
Tesla (and other companies working on automated driving) employ neural networks too. A particular challenge for them is getting enough training data about the situations that arise in driving. That’s why Tesla wants owners of its cars to use their currently incomplete, sometimes problematic version of self-driving; when the car does something wrong, the human driver can push a button to send a video of the situation back to Tesla to incorporate in its machine learning training.
Summary
Look around and you see enormous progress on the tasks we’ve been discussing. My watch — yes, my watch — can transcribe speech accurately and instantaneously! If you had said this to me even ten years ago I would have thought you were nuts.
I am an amateur photographer and the editing tools I use (Adobe Lightroom) can now automatically select parts of scenes (sky, background, people, objects) making it simple to do edits that used to be tedious and error-prone. Want to remove some object from the photo? Pretty easy. Take a picture of a flower on my phone and it can tell you what kind of flower it is.
All of this is made possible by three things:
Artificial neural networks
Massive computing power available for training the networks
Huge amounts of data available on the internet that can be repurposed as training data for machine learning
Importantly, humans don’t have to figure out what visual features characterizes “cat-ness” vs. “dog-ness” in photos, or what distinguishes different letters in handwritten text while at the same time recognizing that certain pen strokes that individuals write differently actually represent the same letter. These sorts of things are all done as part of training the neural networks.
Consequently, if you ask, for example, a computer vision system’s developer to explain how the system decided that a particular photo has a cat in it, not a dog, they won’t be able to tell you. It all comes from the training. And, if a system makes a mistake, the way to correct it is to do additional training.
Besides having a vague understanding of how these systems work, I hope that you now understand that there’s no “magic” intelligence in these systems — it is all math and engineering deployed on large enough scale that machines can now do many tasks that were previously reserved for animals and humans.
What’s Next?
We now have enough background about artificial neural networks and machine learning to begin understanding a bit about the large language models that power ChatGPT and Bard. That will be the topic for the next post. Once we have that behind us, we’ll start looking at the implications of this technology on our society.
U. Marti and H. Bunke. The IAM-database: An English Sentence Database for Off-line Handwriting Recognition. Int. Journal on Document Analysis and Recognition, Volume 5, pages 39 - 46, 2002.
You might remember from algebra that this is the equation of a plane in space with m and s coordinate axes.
Lucid, clear and actually useful. Thanks Lee
Thanks Lee. Wonderfully clear and concise explanation of learning to perform a diverse set of perception tasks in people and computers. Looking forward to what comes next - prediction, compression, creativity, emergence or something else?